스파르타코딩클럽의 "[왕초보] 마케터, 기획자를 위한 실전 데이터 분석" 수업 중 1주차 수업에 대한 개발일지이다.
이번 수업의 목표는 총 3가지이다:
1. 익숙한 엑셀을 통해 데이터 분석 구조 이해,
2. 파이썬과 라이브러리 개념을 이해,
3. 각 데이터 간의 상관관계를 분석.
그럼 왜 데이터를 분석해야하는가?
"하고자 하는 바에 대한 명확한 근거"를 줄 수 있게 도와주는 도구라고 선생님께서는 정의하셨다.
이에 너무 공감한다. 서비스 기획자로 회사에서 일하면서, 현업의 개발자나 디자이너에게 왜 내가 기획하는 내용에 작업해야 하는지 설득하려면, 수치적인 데이터가 있으면 훨씬 설득하기가 수월하다.
특히, 분석한 데이터의 양이 더욱 많을수록, 탐색한 사용자의 pool이 더욱 커지기 때문에 훨씬 근거가 파워풀해진다.
그래서 나의 설득 능력을 강화하기 위해서, 정량적인 데이터를 효과적으로 분석하는 법을 배워야 하는 필요성을 느꼈다. 그래서 이 수업을 수강하게 되었다.
생각보다 데이터를 분석하고 시각화할 수 있는 도구는 가까이에 있었다.
1주차 수업에서는 엑셀로 Kaggle (데이터 사이언스트들에게 유명한 커뮤니티 플랫폼이라고 한다.) 의 가장 유명한 예제인 "타이타닉 생존률 구하기"를 가지고 데이터를 분석했다.
아래와 같은 상황을 전제로 먼저 깔고,
1) 데이터 전처리 → 2) 데이터 분석 → 3) 데이터 시각화 순서로 진행했다.

1) 데이터 전처리: Kaggle에서 제공해준 타이타닉 탑승자 데이터를 "보기 편하게" 정리해준다.
선생님께서 전달해 주신 데이터를 엑셀로 불러온 후 쭉 보니, 공백란이 있었다. 이건 표에 있어도 무의미한 데이터이므로 깔대기(필터) 아이콘으로 공백이 포함된 데이터는 숨김 처리해준다.

2) 데이터 분석: 어떤 데이터 위주로 봐야 하는지 정의한 후, 이를 토대로 분석 툴을 활용한다.
타이타닉 탑승자 데이터에는 총 7가지 항목이 있었다.
- PassengerID: 탑승자의 고유 ID
- Survived: 생존했냐 안했냐 (0: No, 1: Yes)
- Pclass: 탑승 등급
- Sex: 성별 (0: 남성, 1: 여성)
- SibSp: 형제 자매 수
- Parch: 함께 탑승한 부모 또는 자녀의 수
- Fare: 요금

이 데이터를 분석하는 목적인 "생존자와 희생자를 판가름하는 요인"을 찾기 위해서는 Survived라는 항목과 다른 항목들과 연관성이 있는지 없는지를 찾아야 한다.
(여기서 선생님께서 세우신 가설은 다음과 같다: "요금과 탑승 등급이 각각 모두 생존율에 관련이 있을 것이다.")
엑셀에서 이 연관성을 찾을 수 있는 툴을 제공해 준다:
1) 확장 프로그램 > 부가기능 > 부가기능 설치하기 메뉴를 클릭해준 후, "analysis toolpak"를 검색하고 설치해 준다.
설치 완료 후 아래처럼 보인다:
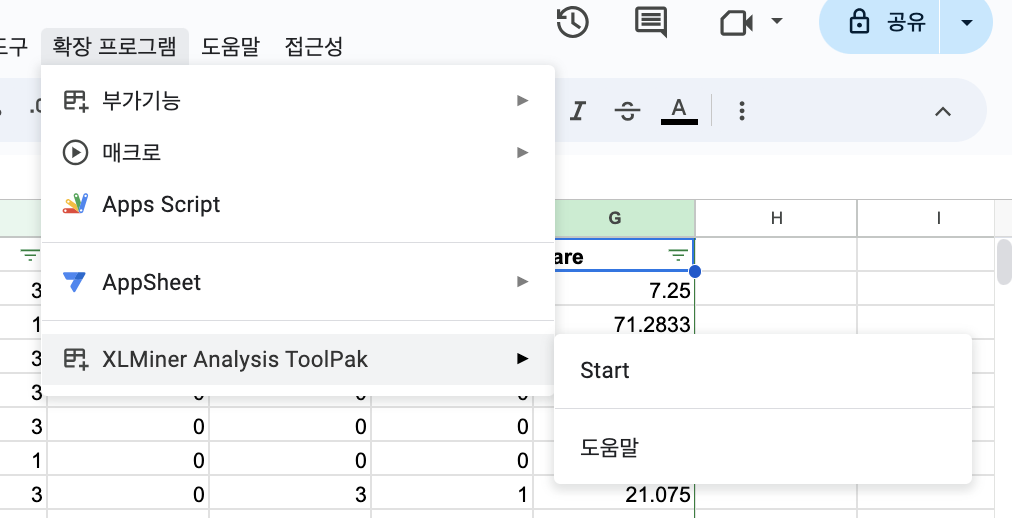
2) 아래 화면에서 start 버튼을 누르면 우측에 메뉴들이 나오는데, 그중에 "Correlation" 메뉴를 클릭한 후,
아래와 같이 데이터를 입력해 주고 OK를 클릭!
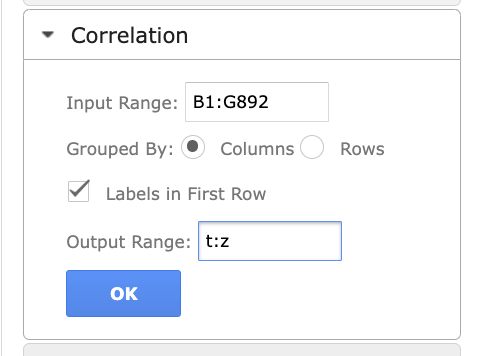
- Input Range: 분석하고 데이터의 셀 번호를 넣는다. (Passenger ID는 단순히 passenger를 구분해주 는 값이므로 필요 없는 데이터이다.)
- Grouped By: 데이터 항목들이 열(column)로 구분되어 있기 때문에, columns로 지정한다.
- Labels in First Row: 분석 완료하면 각 데이터에 라벨을 붙여준다. 그래프를 볼 때 데이터를 구분하기 편하기 때문에 체크!
- Output Range: 분석한 결과를 표시하고 싶은 엑셀의 열 번호를 넣는다.
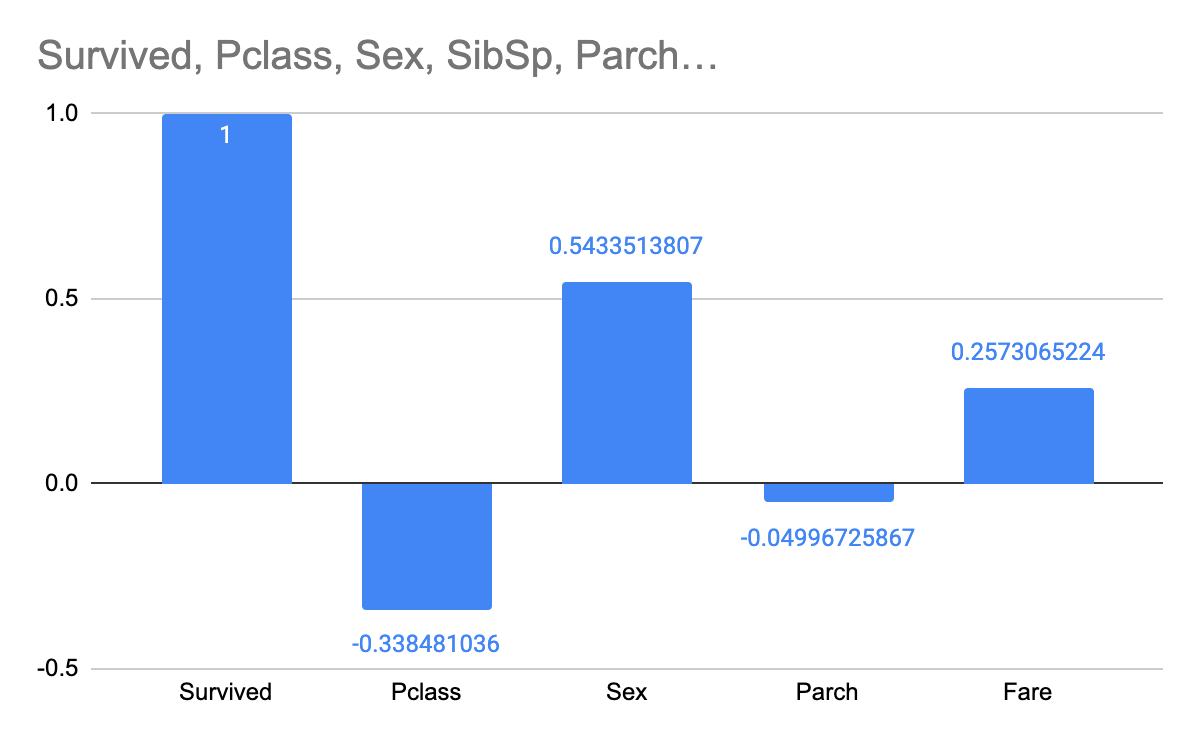
3) 그럼 이렇게 표가 출력된다:
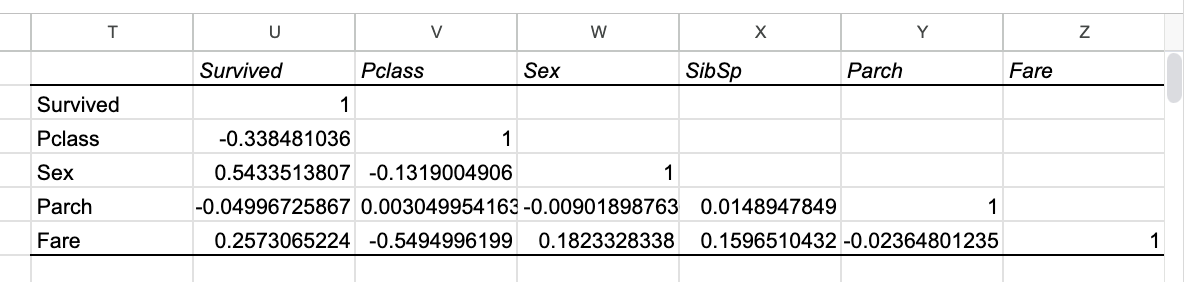
표를 보면 Surived와 Survived는 당연히 같은 값이므로 1,
Survived와 Pclass의 상관관계는 -0.338..으로 음수로 표시되고,
Survived와 Fare의 상관관계는 0.257...으로 양수로 표시된다.
음수, 양수 상관없이 절댓값으로 보았을 때 더 숫자가 클 수록 상관관계가 높다고 생각하면 된다.
(양수는 한 변수가 증가함에 따라 다른 변수도 증가한다는 것을 표현하는 것이고 - Positive correlation,
음수는 한 변수가 증가함에 따라 다른 변수는 감소한다는 것을 표현하는 것이다 - Negative correlation)
숫자로만 보았을 때는 Sex(성별) - Pclass(탑승 등급) - Fare (요금) 순으로 Survived (생존율)와 연관성이 높으므로
생존율은 탑승 등급과 요금과 상관관계가 없지 않다.
3) 데이터 시각화: 분석한 데이터를 보기 쉽게 시각적으로 표현해 준다.
엑셀의 [차트] 만들기 기능을 활용하면 된다.
개인적으로는 데이터를 시각화하는 부분이 수업 예제를 따라 하면서는 별로 안 헷갈렸는데,,
숙제를 하면서는 가장 헷갈렸다🥲
1) 분석한 표를 선택한 후, 삽입 > 차트를 클릭해서 표에 대한 그래프를 생성한다.
2) 여기서 "Survived(생존율)"에 대한 상관관계를 봐야 하므로, [차트 편집기] > [설정] 메뉴의 계열 하단에 Survived 외 다른 항목들은 모두 제거해준다.
그럼 아래처럼 그래프가 나온다.
3) 아래 이미지처럼 항목별로 숫자 데이터도 표시해 주고 싶다면, [차트 편집기] > [맞춤설정] > [계열]에 [데이터 라벨] 체크박스를 켜주면 된다.
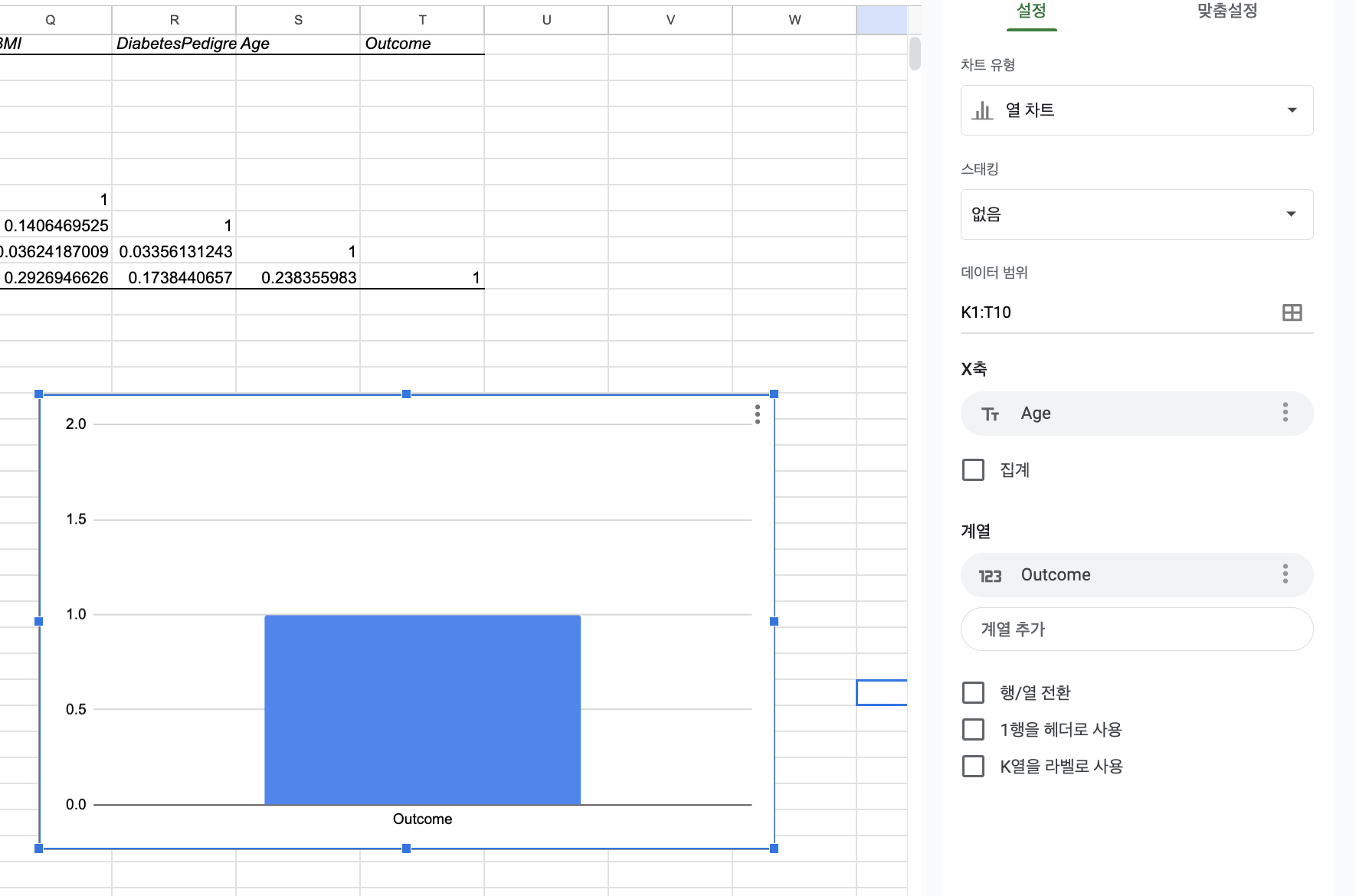
그럼 내가 무엇이 헷갈렸냐!!!
숙제 예제를 하다가 Outcome이라는 항목에 대한 상관관계를 보여주는 그래프를 만들고 싶어서, Outcome 외 다른 항목을 [차트 편집기] > [설정] 메뉴의 계열 하단에서 제거했더니.. X축에 원래 있던 값이 갑자기 이상한 걸로 변하면서 아래 이미지처럼 나왔다.. (멘붕)
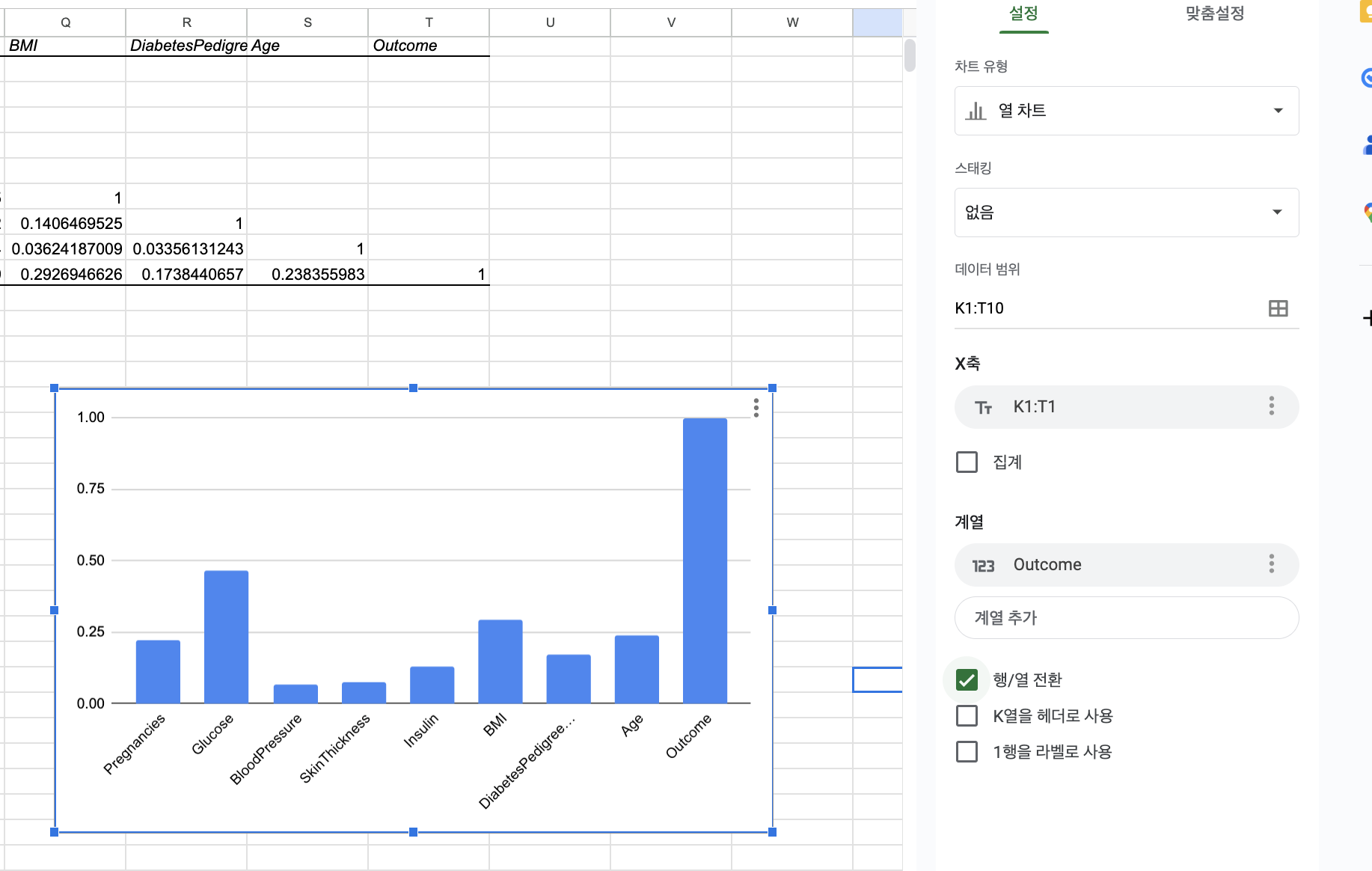
해설 영상을 들어보니 행/열 전환을 설정하면 정상적으로 보인다. 표의 1행이 X축으로 설정되어 있어서인 것 같은데,, 그래도 왜 위처럼 보이는지는 잘 이해는 안 된다.. 아마 1행이 항목명으로 설정되어 있기 때문에 아예 설명할 수 없는 비정상적인 그래프가 보이는 것 같다.
어쨌든 K열 (데이터별 항목)이 X축에 보여야 하는 것이 정상적이라고 한다..
만약 엑셀에서 상관관계 분석을 위해 계열 항목 중 하나 말고 다 삭제했는데 X축으로 설정되었던 값이 자기 멋대로 막 바뀌면..! 행/열 전환 체크해보기를 추천한다.
이렇게 3가지 수업 목표 중 2가지는 클리어했다!
1. 익숙한 엑셀을 통해 데이터 분석 구조 이해,
2. 파이썬과 라이브러리 개념을 이해,
3. 각 데이터 간의 상관관계를 분석.
그럼 2번째 수업 목표인 파이썬과 라이브러리 개념은 왜 나왔냐..
바로 데이터 분석에 있어서 엑셀 활용의 한계점을 파이썬과 파이썬 라이브러리가 해결해 줄 수 있기 때문이다!
대표적으로 엑셀은 대용량 데이터 분석에는 속도에 있어서 취약하다.
그리고 파이썬의 활용 범위가 더 넓다고 한다.
파이썬에서는 pandas (데이터 전처리할 때 유용한 라이브러리), matplotlib (데이터 시각화할 때 유용한 라이브러리) 와 같이 특정한 동작을 쉽게 처리할 수 있는 코드 모음집인 라이브러리도 제공해 주어 더 다양한 형태로 데이터를 분석하고 시각화할 수 있다.
여기서 선생님께서 강조해 주신 내용은,, 코드를 외우지 않아도 된다!!
사실 처음에는 이 말씀이 잘 와닿지 않았는데,, 어떤 목적을 달성하기 위해 어떤 형태의 코드가 필요한지 정도만 인지하면 되는 것 같다!
만약 모르면 Google에 물어보자..!! ㅎㅎ
이렇게 1주차 개발일지는 끝!
위 내용을 요약하자면 아래와 같다:
1. 엑셀로도 간단한 데이터 분석이 가능하다.
2. 가설 수립 후, 데이터를 분석하기 위해서는 1) 데이터 전처리 → 2) 데이터 분석 → 3) 데이터 시각화의 step을 거친다.
'데이터 분석일지 > 마케터, 기획자를 위한 실전 데이터 분석' 카테고리의 다른 글
| 피벗 테이블과 코호트 분석 히트맵 시각화하기 (2) | 2024.06.04 |
|---|---|
| 실무 상황에서 데이터 분석하기 2탄 - 데이터 시각화 (2) | 2024.06.03 |
| 실무 상황에서 데이터 분석하기 (0) | 2024.05.30 |
| Numpy와 Seaborn 라이브러리로 데이터 분석하기 (0) | 2024.05.08 |
| Colab으로 본격 데이터 분석하기 (0) | 2024.04.30 |