SQLD 자격증을 취득하기 위하여 스파르타코딩클럽의 "SQLD 자격증 채린지" 수업을 수강한 내용을 복습 차원에서 정리한 내용이다.
SQLD 자격증 챌린지
단기간 SQLD 격파가 가능한, 격파르타 차별점
certificate-sqld.oopy.io
2일차 수업의 목표는 데이터 모델링을 이해하는 것이다.
아래 목차와 같이 내용을 정리할 예정이다.
- 모델링의 이해
- 데이터 모델링의 중요성
- 3층 스키마 (3-Level Schema)
- 데이터 모델링의 요소와 ERD
2일차 수업 내용은 1과목인 데이터 모델링의 이해의 일부이다.
1. 모델링이 이해
데이터 모델링의 정의:
- 정보 시스템 구축을 위해 (서비스를 만들기 위해서) 데이터 관점의 업무를 분석하는 과정.
- 데이터 모델링은 개발/구현만을 위한 단계가 아니다. 데이터 모델링은 비즈니스/사업/서비스를 어떻게 만들어 나갈지 분석하는 과정이다.
- 현실 세계의 데이터를 약속된 표기법에 의해 표현하는 과정.
- 데이터베이스를 구축하기 위한 분석 및 설계의 과정.
데이터 모델링의 목적:
- 업무에 필요한 정보를 정확하게 정의하고, 표현하여 업무를 분석.
- 분석 모델을 통해 실제 데이터 베이스를 생성하여 데이터를 관리.
데이터 모델이 제공하는 기능:
| 기능 | 설명 |
| 시각화 | 시스템을 원하는 모습으로 시각화해서 보여줄 수 있다. |
| 문서화 | 시스템의 구조와 행동을 문서화하다. |
| 구체화 | 특정한 목표에 따라 구체화된 상세 수준의 표현 방법을 제공한다. |
| 구조화된 틀 제공 | 시스템을 구축하는 구조화된 틀을 제공한다. |
| 다양한 관점 제공 | 다양한 영역에 집중하기 위해 다른 영역의 세부 사항은 숨기는 다양한 관점을 제공한다. |
모델링의 특징:
복잡한 형식에 맞추어 표현하여(추상화하여) 단순해지니, 명확해진다.
| 특징 | 설명 |
| 추상화 (Abstraction) | 현실세계를 일정한 형식에 맞추어 표현하는 것. |
| 단순화 (Simplification) | 복잡한 현실세계를 약속된 규칙에 기반한 제한된 표기법이나 언어로 표현. |
| 명확화 (Clarify) | 누구나 이해하기 쉽게 대상에 대한 애매모호함을 제거하고 현상을 정확하게 기술한 것. |
데이터 모델링의 3가지 단계
현실 세계 → (1: 개념적 모델링) → 개념적 구조 → (2: 논리적 모델링) → 논리적 구조 → (3: 물리적 모델링) → 데이터베이스
| No. | 단계 | 설명 |
| 1 | 개념적 데이터 모델링 (Conceptual Data Modeling) |
- 맨 처음 현실세계를 모델링하는 단계. - 데이터의 요구사항을 찾고 분석하는 과정. - 복잡하지 않고 중요한 부분을 위주로 모델링하는 단계. - 추상화 수준이 가장 높고 업무 중심적인 모델링. - 전사적 관점에서 기업의 데이터 모델링. |
| 2 | 논리적 데이터 모델링 (Logical Data Modeling) |
- 비즈니스 과정에서 나타나는 정보의 논리적인 구조와 규칙을 명확하게 표현하는 기법/과정. - 프로세스를 잡는 과정. 데이터를 어떻게, 어떤 프로세스를 가질까?를 구상하는 모델링 과정. - 누가 (Who), 어떻게 (How: Process) 그리고 전산화와는 별개로 비즈니스 데이터에 존재하는 사실을 인식하여 기록하는 것. - 정규화를 수행하여 데이터 모델의 독립성 확보. (정규화: 논리 데이터 모델의 일관성을 확보하고 중복을 제거하여 보다 신뢰성 있는 데이터 구조를 얻는 방법.) |
| 3 | 물리적 데이터 모델링 (Physical Data Modelnig) |
- 논리적 데이터 모델이 데이터 저장소로서 어떻게 컴퓨터 하드웨어에 표현될 것인지를 다루는 과정 (논리적 데이터 모델이 어떻게 실제로 컴퓨터로 들어갈지.) - 구축할 데이터 베이스 관리 시스템에 테이블, 인덱스 등을 성장하는 단계. - 성능, 보안, 가용성을 고려하여 구축. |
데이터 모델링을 바라보는 관점
| 관점 | 설명 |
| 데이터 관점 (Data → What) | - 업무가 어떤 데이터와 관련 있는지 모델링하는 방법에 대해 고민하는 관점. - 비즈니스 프로세스에서 사용되는 데이터. |
| 프로세스 관점 (Process → How) | - 우리가 뽑은 데이터 업무가 무엇을 해야 하는지 모델링하는 방법에 대해 고민하는 관점. - 도메인 분석, 시나리오 분석. |
| 데이터와 프로세스의 상관 관점 (Intersection: Data vs. Process) | - 일에 의해 데이터가 어떤 변화가 일어나는지에 대해 초점을 맞추는 관점. - 업무가 처리하는 일의 방법에 따라 데이터는 어떤 영향을 받고 있는지. - CRUD (Create, Read, Update, Delete) 분석. |
2. 데이터 모델링의 중요성
(★수업목표: 모델링의 이해를 바탕으로 데이터 모델링의 중요성과 프로젝트 관리 방법론을 학습)
데이터 모델링의 중요성 및 유의점
- 파급효과 (Leverage): 모델링을 잘 설계하기 위해서는, 데이터가 흘러가는 것을 전체의 관점에서 바라볼 수 있어야 한다. 구체적인 내용은 변해도, 큰 구조는 변하지 않도록 만들어야 한다. → 사소한 내용을 수정해도, 큰 파급효과를 가져오면 안 된다.
- 간결한 표현 (Conciseness): 데이터 모델은 구축할 시스템의 정보에 대한 요구사항과 한계점을 가장 명확하고 간결하게 표현할 수 있는 도구이다.
- 데이터 품질 (Data Quality): 좋은 데이터를 모을 수 있도록 데이터 구조를 잘 설계해야 한다.
- 데이터 품질의 기준:
- 중복 (Duplication): 여러 곳에 같은 정보를 중복해서 저장하면 안 된다.
- 비유연성 (Inflexibility): 환경이 바뀌었을 때 데이터가 사용 가능해야 한다. 사소한 업무의 변화에도 유연하게 대처할 수 있도록 데이터 모델의 유지보수가 쉬워야 한다.
- 비일관성 (Inconsistency): 중복이 없다고 해도 일관적이지 않은 데이터가 나타날 수 있다. 데이터와 데이터 간의 상호 연관 관계에 대해 명확하게 정의해야지 일관성이 깨지지 않는다.
- 데이터 품질의 기준:
프로젝트 라이프 사이클에서의 데이터 모델링
프로젝트 관리 방법론에는 크게 2가지 방법론이 있다.
- 폭포수 모델 (Waterfall): A, B, C, D단계가 명확하다. 프로제긑의 범위가 명확할 때 적용한다. 프로젝트의 크기가 작을 때 적용한다.
- 애자일 모델 (Agile): 최소 기능 (MVP)을 만들어보고 굴려본 후 살을 붙인다. → 점진적으로 프로젝트의 크기를 불려나가는 것.
| 프로젝트 라이프 사이클 (Waterfall 기반) |
정보공학, 구조적 방법론 | 개발 |
| 분석 | 논리 및 개념 데이터 모델링 | 프로세스 모델링 |
| 설계 | 물리 데이터 모델링 | AP 설계 |
| 개발 | DB 구축, 변경, 관리 | AP 개발 |
| 테스트 | DB 튜닝 | AP 테스트 |
| 전환/이행 | DB 전환 | AP 설치 |
데이터 모델링의 이해 관계자
정보 시스템을 구축하는 모든 사람은 데이터 모델링을 전문적으로 할 수 있거나, 완성된 모델을 적어도 정확하게 해석할 수 있어야 한다.
+ 기획자, IT비종사자, 비전공자도 "정보화(IT)"와 관련된 업무를 하고 있다면 데이터 모델링에 대한 개념과 세부사항에 대해 알아야 한다.
→ WHY? 업무 소통이 가능해야 하기 때문.
3. 3층 스키마 (3-Level Schema)
(★수업목표: 데이터 독립성 확보에 대한 방법을 학습한다.)
데이터 독립성의 필요성
데이터 모델링의 과정에서 신경써야 하는 것 중 하나는 데이터의 일체적 구성이다.
일체적 구성이란 일관된 형태로 데이터를 수집한느 것. = 데이터의 독립적 구성.
(A, B, C 데이터가 있는데 A를 수정한다고 해도 B, C에 영향이 가지 않는 구조가 데이터 독립성이다.)
- 데이터 독립성이 필요한 이유:
- 유지보수 비용 증가
- 유지보수 중복성 증가
- 데이터 복잡도 증가
- 요구사항 대응 저하
- 데이터 독립성의 기대효과:
- 각 View의 독립성을 유지하고 계층별 View에 영향을 주지 않고 변경이 가능하다.
- 단계별 Schema에 따라 데이터 정의어 (DDL)와 데이터 조작어 (DML)가 다르게 제공된다.
→ 응용 프로그램과 물리적 데이터 베이스를 분리하자!
데이터베이스의 3단계 구조 (3층 스키마)
데이터 베이스를 관점에 따라서 3단계로 나누어서 관계를 정의한 ANSI 표준.
→ 사용자, 설계자, 개발자가 데이터 베이스를 보는 관점에 따라 데이터 베이스를 기술하고 이들간의 관계를 정의한 표준.

| 항목 | 내용 | 비고 |
| 외부 스키마 (External Schema) |
- 유저 어플리케이션(프로그램)은 데이터 베이스 시스템의 최상위 단계. (우리가 사용하는 프로그램들이 위치하는 단계) - View 단계 여러 개의 사용자 관점으로 구성. - 개별 사용자가 보는 DB 스키마. - 실제로 관심 있는 데이터 베이스 부분을 설명하고 나머지는 감춘다. (3층 레이어로 구성하는 이유) |
- 사용자 관점. - 접근하는 특성에 따른 스키마를 구성. |
| 개념 스키마 (Conceptual Schema) |
- 최상위와 최하위를 연결해주는 단계 → 데이터 베이스를 조금 추상화하는 단계. (우리 데이터가 어떻게 구성되어 있어~를 보는 단계.) - 전체적인 구조를 표현. - 데이터 베이스의 물리적 저장 구조에 대한 부분을 숨기고, 데이터의 전체적인 구조와 관계에 대해 집중. - 모든 사용자 관점을 통합한 조직 전체의 DB를 기술. - 모든 응용 시스템들이나 사용자들이 필요로 하는 데이터를 통합한 조직 전체의 DB를 기술한 것. - DB에 저장하는 데이터와 그들간의 관계를 표현하는 스키마. |
- 설계자 관점, 통합 관점. - 통합 데이터 베이스 구조. |
| 내부 스키마 (Internal Schema) |
- 물리적 데이터베이스는 최하위에 위치. (실제로 데이터가 저장되어 있는 위치.) - 내부 단계, 내부 스키마로 구성. - DB가 물리적으로 저장된 형식. - 물리적인 장치에서 데이터가 실제적으로 저장되는 완전히 구체적인 방법을 표현하는 스키마. |
- 개발자 관점. - 물리적 저장 구조. |
→ 데이터 베이스를 3가지의 큰 범주로 분리해보자는 컨셉.
- 사상(mapping): 각각의 범주간의 요청/응답을 전송하는 것.
- 외부 스키마에서 요청이 들어오면 DBMS에 의해 개념 스키마 - 내부 스키마로 전달됨. 여기에서 요청과 응답이 변환하는 프로세스를 사상(mapping)이라고 함.
- 개념 스키마: 전체 데이터 베이스의 설계를 설명할 수 있는 모델 (구조, 관계 등). 데이터 구조의 구현 정보와 같은 내부 상세 정보는 보지 못함.
- 내부 스키마: 물리적 저장 구조를 맞춘 모델.
데이터의 독립성 (Data Independence)
상위 스키마를 변경하지 않고 하나의 계층에서 스키마를 변경할 수 있는 능력.
데이터 베이스의 여러 레벨에서 구조를 수정할 때, 하위 레벨 스키마를 변경하더라도 상위 레벨의 스키마를 건드릴 필요가 없는 것 (영향을 미치지 않음.)
3층 스키마의 독립성 - 데이터의 독립성 개념을 3층 스키마에 적용.
| 독립성 | 설명 | 특징 |
| 논리적 독립성 | - 개념 스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원. - 논리적 구조가 변경되어도 응용 프로그램에 영향이 없음. |
- 사용자 특성에 맞게 변경 가능. - 통합 구조로 변경 가능. |
| 물리적 독립성 | - 내부 스키마가 변경되어도 개념 스키마는 영향을 받지 않도록 지원. - 저장 장치의 구조 변경은 응용 프로그램과 개념 스키마에 영향을 주지 않는다. |
- 물리적 구조의 영향 없이 개념 구조로 변경 가능. - 개념 구조의 영향 없이 물리적인 구조로 변경 가능. |
→ 검색 속도를 높이기 위해 데이터가 저장되는 파일의 구조를 바꼈다고 해서 (내부 스키마), 전체적인 데이터 구조/설계가 달라지거나 (개념 스키마), 응용 프로그램단이 (외부 스키마) 변경되면 안된다는 것.
→ 데이터 베이스를 바라보는 관점에 따라 3가지로 나눌 수 있다! 그 각각은 논리적/물리적으로 독립적이면 좋다!
4. 데이터 모델링의 요소와 ERD
(★수업목표: 데이터 모델링의 중요한 3가지 개념에 대해 학습한다.)
데이터 모델링을 구성하는 3가지 중요 요소
| 요소 | 설명 | 예시 |
| 엔티티 (Entity) | - 업무가 관여하는 어떤 것 (thing) - 사물이나 사건을 바라볼 때 전체를 지칭하는 용어. - 초점이 맞추어 있는지. - 눈에 보이는 개념이든 데이터 모델링에서 사용된느 하나의 대상, 객체. |
- 학생, 미스터리 사건 등 |
| 속성 (Attribute) | - 어떤 것이 갖는 성격. - Entity가 가진 성격, Entity가 지닐 수 있는 여러 특징. |
- 키, 몸무게, 성격, 취미 등 |
| 관계 (Relationship) | - 업무가 갖는 어떤 것 간의 관계. - Entity와 Entity가 서로 간의 관계를 가질 수 있다. |
- 친구 사이, 연인 사이, 가족 관계, 직장 선후배 관계, 헬스장과 트레이너는 한 명의 트레이너가 여러명의 고객을 응대하는 관계임으로 1:N 관계 |
데이터 모델링을 위한 ERD
- ERD (Entity Relationship Diagram): 데이터들의 관계를 나타낸 도표.
- ERD 작성법:
- 엔티티를 정의하고 그린다.
- 엔티티를 적절하게 배치한다. (가장 중요한 엔티티를 좌측 상단에 배치하고, 이것을 중심으로 다른 엔티티들을 나열한다. 왼쪽에서 오른쪽, 위쪽에서 아래쪽으로)
- 엔티티간의 관계를 설정한다.
- 관계명을 서술한다.
- 관계의 참여도를 기술한다. (특정 엔티티와 다른 엔티티 간의 관계 수를 의미.)
- 관계의 필수 여부를 기술한다.
데이터 모델 표기법
1) IE/Crow's Foot (엔티티를 표기)표기법과 2) Barker/Case*Method (관계를 표기) 표기법
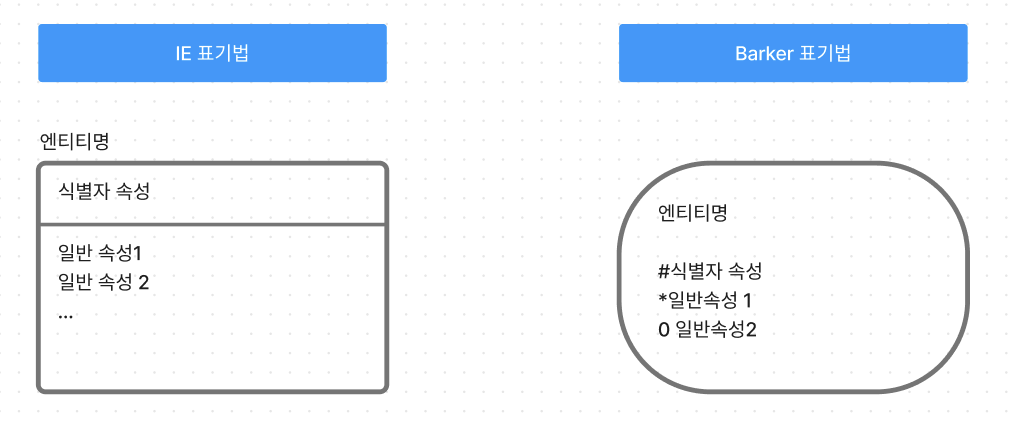
- 식별자 속성: 고유한 속성 (예: 군번, 주민등록번호)
- Barker 표기법 참고사항
- # : 식별자 속성 앞에 표기
- * : 필수 속성 앞에 표기
- ○ : 선택 송성 앞에 표기
좋은 데이터 모델의 요소
절대 기준은 존재하지 않지만, 전반적인 상황에서 좋은 데이터 모델로 평가할 수 있는 요소.
- 완전성 (Completeness): 모든 데이터가 모델에 정의되어 있어야 한다.
- 중복 제재 (Non-Redundancy): 하나의 데이터 베이스 내에 동일한 사실은 한 번만 기록해야 한다. (예: 나이라는 컬럼과 생년월일 컬럼은 중복됨.)
- 업무 규칙 (Business Rules): 데이터 모델링 과정에서 도출되는 수많은 업무 규정을 데이터 모델에 표현할 수 있어야 한다. (예: 내가 만드는 서비스의 비즈니스가 어떻게 구성되어야 하는지 비즈니스 모델에 표현되어야 한다. - 보험 회사의 급여, 급여별 항목 등이 데이터 모델에 있어야 함.)
- 데이터 재사용 (Data Reusability): 언제든 다시 사용할 수 있는 형태로 가공되고 보관되어야 함.
- 의사소통 (Communication): 의사소통 도구로서의 역할.
- 통합성 (Integration): 동일한 데이터 구조는 조직 전체에 한 번만 정의되어야 하고, 이를 여러 다른 영역에서 참조, 활용하는 것이 가장 바람직하다.
'데이터 분석일지 > SQLD 준비' 카테고리의 다른 글
| SQLD 자격증 챌린지 6일차 강의: SQL 실습 환경 구성, 관계형 데이터베이스 알아보기 (0) | 2024.05.13 |
|---|---|
| SQLD 자격증 챌린지 5일차 강의: 데이터 모델 및 SQL 파트 개념의 시작 (1) | 2024.05.12 |
| SQLD 자격증 챌린지 4일차 강의: 데이터 성능을 위한 정규화와 비정규화 (0) | 2024.05.11 |
| SQLD 자격증 챌린지 3일차 강의: 데이터 모델링의 4가지 요소 (0) | 2024.05.09 |
| SQLD 자격증 챌린지 1일차 강의: SQLD (0) | 2024.05.09 |